Searching for swear words in the Enron corpus
Tags: projects, visualization
I recently downloaded the Enron corpus to try to visualize some interesting features. As a first step, I wanted to analyse how many swear words are used in the corpus. I wanted to find out if there are some users with a “saltier“ language than others.
Processing the data
I am only using the simplest procedure for walking through the data: First, I defined a list of offensive words (with a little help from Wikipedia, of course). Second, I used a basic Python script to process each e-mail, tokenize it, and check the words against the list of profanity. The counts are then tallied and printed out. Here’s a rough draft of the script:
#!/usr/bin/env python
import collections
import email
import hashlib
import nltk
import os
directory = "maildir/"
swearWordsPerPerson = collections.Counter()
swearWordsTotal = collections.Counter()
swearWords = set()
parser = email.parser.HeaderParser()
with open("Swear_words.txt") as f:
for line in f:
swearWords.add( line.rstrip() )
for root, _, files in os.walk(directory):
p = os.path.normpath(root)
p = p.split(os.sep)
person = ""
if len(p) >= 2:
person = p[1]
print("Processing '%s'..." % person)
for name in files:
path = os.path.join(root,name)
with open(path, errors="ignore", encoding="utf-8") as f:
text = f.read()
text = parser.parsestr(text, headersonly=True).get_payload()
text = text.encode("utf-8")
words = nltk.word_tokenize(text.decode("utf-8").lower())
for index,word in enumerate(words):
if word in swearWords:
swearWordsPerPerson[person] += 1
swearWordsTotal[word] += 1
print("...finished")
print("%s: %d" % (person, swearWordsPerPerson[person]))
print("THE SWEARERS\n")
for person, numSwears in swearWordsPerPerson.most_common():
print(" %s: %d" % (person, numSwears))
print("")
print("THE SWEARS\n")
for swear, number in swearWordsTotal.most_common():
print(" %s: %d" % (swear, number))The conversion of text from each e-mail looks needlessly elaborate, but it is required to ensure that words in the e-mail headers are not counted. Of course, I am not trying to detect any fancy things such as messages that have been forwarded multiple times. Furthermore, I have excluded some words from the list of swears in order not to trigger any false positives. One of the executives is called “Dick Jenkins”, and some of his co-workers refer to him by his first name, so…
The swearers
First, let’s look at a histogram of the absolute number of swears:
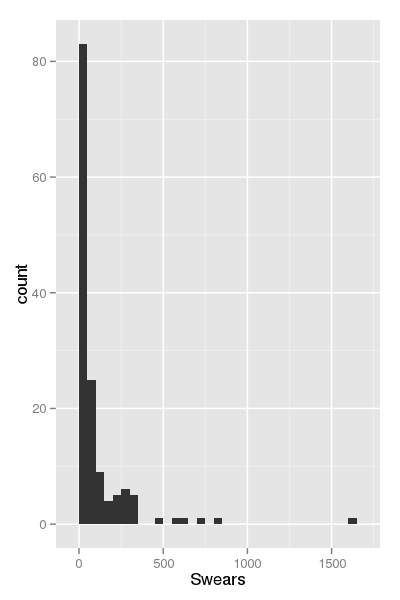
We can see that there are only few people who seem to use many swears. However, this is not normalized against the number of e-mails each person received. Let’s do this next!
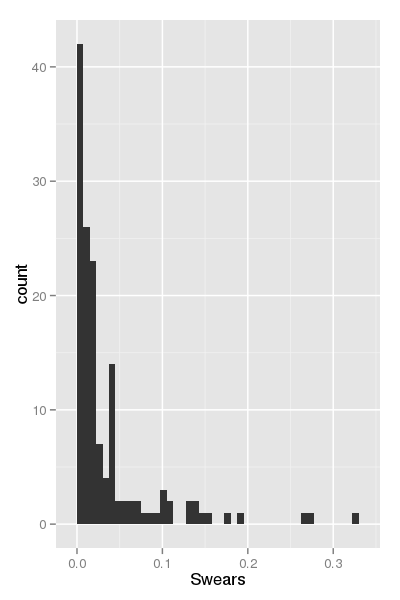
The pattern is similar, but the outliers are now “normalized” in a sense. If we focus on a normalized swear count of larger than 0.25 (with a unit of “swears per e-mail”), we are left with the following persons:
lucci-p 0.33
lenhart-m 0.28
brawner-s 0.27
quigley-d 0.19
ring-a 0.18
dorland-c 0.15
All the remaining 144 (!) persons use less than 0.15 swear words per e-mail.
The swears
So, what are the top ten swear words in all e-mails? Without further ado, here is a partially censored list (I don’t want to lose my family-friendly rating):
hell 2033
a**: 1724
sh*t 1583
sex 1521
balls 1235
d*mn 915
b*tch 711
f*ck 690
butt 615
crap 612
Conclusion
Does this mean that the Enron people like to swear? Unfortunately, no. First of all, the context of a word is extremely important. In some cases, hell might be a misspelling of he’ll. Second, the swear count might be multiplied by people forwarding (or replying) e-mails without removing the old content.
Upon further inspection, it turns out that most of the swear words are used in personal communications. People are forwarding the usual dirty jokes among their friends and co-workers, who in turn reply with a salty joke themselves.
The take-away messages from this experiment are:
- Figuring out words in context is hard.
- Analysing a corpus such as the Enron e-mails is also hard.
- Natural language is even harder.