Postincrement vs. preincrement in C++
Tags: programming
The debate about whether to use postincrement (i++) or preincrement (++i) when writing a loop in
C++ has been going on for a very long time. It is probably one of the most favourite programming
interview questions ever.
Let’s take a closer look at what modern compilers have to say about it. First, this is the test code
for postincrement, which I shall refer to as postincrement.cc:
#include <iostream>
int main(int, char**)
{
for( unsigned i = 0; i < 42; i++ )
std::cout << i << std::endl;
return 0;
}Likewise, preincrement.cc refers to the following code:
#include <iostream>
int main(int, char**)
{
for( unsigned i = 0; i < 42; ++i )
std::cout << i << std::endl;
return 0;
}In the following, let us take a look at the assembly code generate by both gcc 4.9.2 and clang 3.5.1. Fortunate for me, I don’t have to actually understand the assembly code. It is perfectly sufficient to look at the differences between the two codes. If there are none, the two programs behave exactly the same.
Let’s try it with gcc first (using -O0 to disable optimizations in order no to bias the results):
$ g++ -O0 -S postincrement.cc
$ g++ -O0 -S preincrement.cc
The result of diff postincrement.s preincrement.s is:
1c1
< .file "postincrement.cc"
---
> .file "preincrement.cc"
Thus, gcc generates the same code twice. This works of course without providing -O0, as well. So,
how does clang fare?
$ clang -O0 -S postincrement.cc
$ clang -O0 -S preincrement.cc
The result of diff postincrement.s preincrement.s is:
2c2
< .file "postincrement.cc"
---
> .file "preincrement.cc"
79,80c79,80
< .type _GLOBAL__sub_I_postincrement.cc,@function
< _GLOBAL__sub_I_postincrement.cc: # @_GLOBAL__sub_I_postincrement.cc
---
> .type _GLOBAL__sub_I_preincrement.cc,@function
> _GLOBAL__sub_I_preincrement.cc: # @_GLOBAL__sub_I_preincrement.cc
95c95
< .size _GLOBAL__sub_I_postincrement.cc, .Ltmp11-_GLOBAL__sub_I_postincrement.cc
---
> .size _GLOBAL__sub_I_preincrement.cc, .Ltmp11-_GLOBAL__sub_I_preincrement.cc
103c103
< .quad _GLOBAL__sub_I_postincrement.cc
---
> .quad _GLOBAL__sub_I_preincrement.cc
Remember when I said to you that we did not have to understand assembly code for this experiment? Well, I lied. A little. However, although my assembly skills are extremely rusty, you may believe when I say that all differences depicted above merely pertain to renamed segments. There’s nothing in there about spurious variable copies.
For integral types, there is thus apparently no difference between the two variants.
Let’s spice it up by using iterators! Here’s postincrement-iterator.cc:
#include <iostream>
#include <numeric>
#include <vector>
int main(int, char**)
{
std::vector<unsigned> v( 42 );
std::iota( v.begin(), v.end(), 0 );
for( auto it = v.begin(); it != v.end(); it++ )
std::cout << *it << std::endl;
return 0;
}And here’s preincrement-iterator.cc:
#include <iostream>
#include <numeric>
#include <vector>
int main(int, char**)
{
std::vector<unsigned> v( 42 );
std::iota( v.begin(), v.end(), 0 );
for( auto it = v.begin(); it != v.end(); ++it )
std::cout << *it << std::endl;
return 0;
}Here, we experience a completely different behaviour. Both gcc and clang create an extra copy during the iteration–however, this extra copy does not seem to be used anywhere. clang, for example, creates the following assembly code for the postincrement operator:
.LBB1_7: # in Loop: Header=BB1_3 Depth=1
leaq -88(%rbp), %rdi
movl $0, %esi
callq _ZN9__gnu_cxx17__normal_iteratorIPjSt6vectorIjSaIjEEEppEi
movq %rax, -104(%rbp)
jmp .LBB1_3
The mangled symbol _ZN9__gnu_cxx17__normal_iteratorIPjSt6vectorIjSaIjEEEppEi refers to the
postincrement operator. There is an additional instruction, movl $0, %esi, which is not required
for the preincrement operator. So, the postincrement version requires more CPU cycles than the
preincrement version.
Let’s briefly take a look at how bad the problem is:
#include <chrono>
#include <iostream>
#include <numeric>
#include <vector>
int main(int, char**)
{
std::vector<unsigned> v1( 1000000 );
std::vector<unsigned> v2( 1000000 );
std::iota( v1.begin(), v1.end(), 1 );
std::iota( v2.begin(), v2.end(), 2 );
std::chrono::time_point<std::chrono::high_resolution_clock> t1, t2, t3;
t1 = std::chrono::high_resolution_clock::now();
for( auto it = v1.begin(); it != v1.end(); it++ )
*it *= 2;
t2 = std::chrono::high_resolution_clock::now();
for( auto it = v2.begin(); it != v2.end(); ++it )
*it *= 2;
t3 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> d1 = t2 - t1;
std::chrono::duration<double> d2 = t3 - t2;
std::cout << "Postincrement: " << std::chrono::duration_cast<std::chrono::microseconds>( d1 ).count() << "us" << std::endl
<< "Preincrement: " << std::chrono::duration_cast<std::chrono::microseconds>( d2 ).count() << "us" << std::endl;
return 0;
}This yields:
$ g++ -std=c++11 increment-timing.cc; ./a.out
Postincrement: 31531us
Preincrement: 20867us
For “real” measurements, this should of course be run numerous times. These are the results:
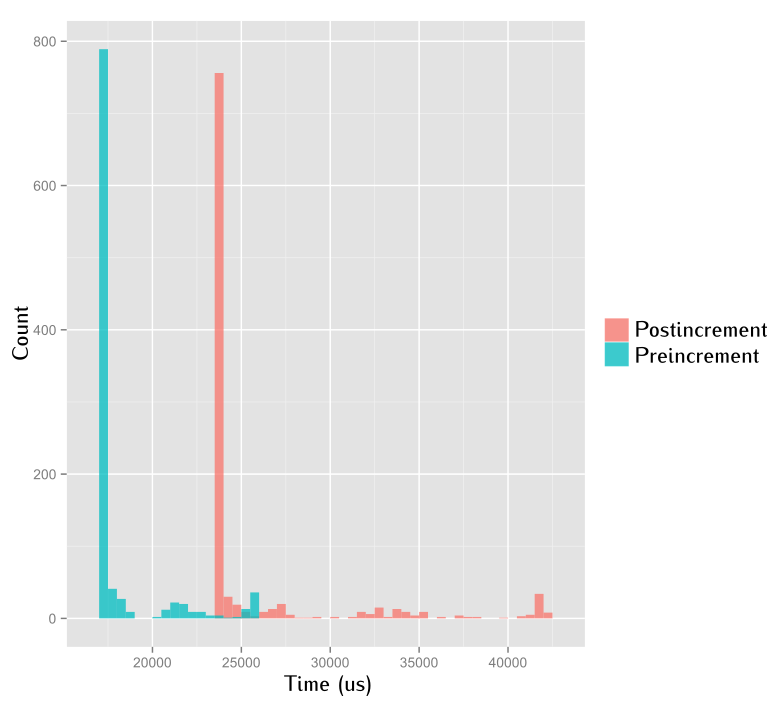
Thus, preincrement is definitely faster than postincrement for iterators (or, to be even more precise, certain kinds of iterators).